import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from datetime import datetime
import missingno as msno
import statsmodels.api as sm
from statsmodels.formula.api import ols
from scipy import stats
from sklearn.preprocessing import MinMaxScaler, StandardScaler, RobustScaler基础数据处理
本节主要学习对基本数据进行操作和修改,并进行基本的分析。
首先导入所需的包。
数据转换
数据转换是数据处理的重要环节,包括类型转换、分布变换和自定义转换(如基于业务逻辑的复杂计算)。
读取数据
数据类型转换
常见的 CSV 格式是没有数据类型信息的,通常程序在读取时对数据类型进行猜测。如果程序猜测错误,那么数据的类型就不是期望的类型。此时,就需要对数据类型进行转换。
日期类型
日期的格式比较复杂,通常都是以字符串的方式进行读取。
可以使用 pandas 提供的 to_datetime 函数进行转换。
pd.to_datetime() 该函数的主要参数及说明如下表所示:
format: 手动指定日期时间的格式字符串(如'%Y-%m-%d')dayfirst: 解析歧义日期(如”01/02/2025”)时,是否以“日”为优先[reference:5]。yearfirst: 解析歧义日期时,是否以“年”为优先。其优先级高于dayfirst[reference:6]。utc: 控制时区处理[reference:7]:True: 始终返回UTC时区的时间,将无时区输入“本地化”为UTC,有时区输入则“转换”为UTC。False: (默认) 保持输入的时区属性。
unit: 指定整数/浮点数类型arg的时间单位[reference:8]。常用单位有:'D'(天),'s'(秒),'ms'(毫秒),'us'(微秒),'ns'(纳秒)。
其他类型
分布变换
一个常见的操作是将左偏的数据变换为正态化的数据。
Tip
如果是右偏,则使用指数函数变换
通过直方图观察数据分布情况
fig, facets = plt.subplots(1, 2)
facets[0].hist(aqi_data['aqi'], bins=30, edgecolor='black', alpha=0.7, color='steelblue')
facets[0].set_xlabel('AQI', fontsize=12)
facets[0].set_ylabel('Frequency', fontsize=12)
facets[1].hist(aqi_data['aqi_log'], bins=30, edgecolor='black', alpha=0.7, color='steelblue')
facets[1].set_xlabel('log(AQI)', fontsize=12)
facets[1].set_ylabel('Frequency', fontsize=12)
plt.tight_layout()
plt.show()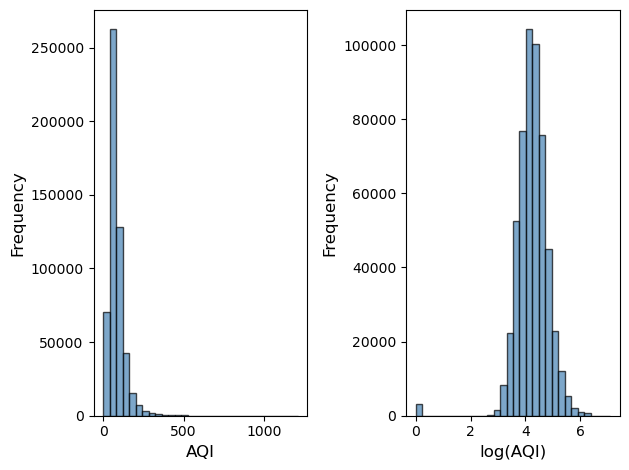
自定义转换
自定义转换允许根据业务需求创建新变量。例如,根据AQI值划分污染等级,或计算多个污染物的综合指数。
条件转换
使用np.select()或pd.cut()进行条件赋值。
array(['中度污染', '中度污染', '重度污染', ..., '良', '优', '良'],
shape=(534176,), dtype='<U4')0 中度污染
1 中度污染
2 重度污染
3 中度污染
4 中度污染
...
534171 良
534172 良
534173 良
534174 优
534175 良
Name: aqi, Length: 534176, dtype: category
Categories (6, str): ['优' < '良' < '轻度污染' < '中度污染' < '重度污染' < '严重污染']多变量综合计算
创建综合污染指数,例如加权平均多个污染物浓度。
| pm25 | pm10 | so2 | co | no2 | o3 | composite_index | |
|---|---|---|---|---|---|---|---|
| 0 | 146 | 173 | 72 | 2.3 | 107 | 47 | 111.93 |
| 1 | 148 | 176 | 70 | 2.1 | 113 | 41 | 113.51 |
| 2 | 210 | 187 | 71 | 1.7 | 83 | 25 | 126.77 |
| 3 | 118 | 148 | 56 | 1.4 | 83 | 65 | 93.84 |
| 4 | 121 | 142 | 50 | 1.6 | 87 | 65 | 93.76 |
应用函数进行转换
使用apply()与自定义函数进行复杂转换。
pollutant_names = ['pm25', 'pm10', 'so2', 'co', 'no2', 'o3']
def major_pollutant(cityname, time_point, aqi, pm25, pm10, so2, co, no2, o3, rank):
pollutants = [pm25, pm10, so2, co, no2, o3]
major_index = pollutants.index(max(pollutants))
return pollutant_names[major_index]
# 应用函数
aqi_data.apply(
lambda row: major_pollutant(*row), axis=1
)Warning
- apply 通常比向量化计算慢,但比使用
for进行迭代要快。 - 只有当难以使用向量化计算时再考虑使用
apply。
应用函数进行转换
0 pm10
1 pm10
2 pm25
3 pm10
4 pm10
...
534171 pm10
534172 pm10
534173 pm10
534174 o3
534175 pm10
Length: 534176, dtype: str数据归一化与标准化
数据归一化是将数据按比例缩放,使之落入一个特定区间,消除量纲影响,使不同特征具有可比性。标准化是将数据转换为均值为0、标准差为1的分布。以下是几种常用的归一化和标准化方法:
1. Min-Max归一化(最小-最大标准化)
\[x' = \frac{x - \min(x)}{\max(x) - \min(x)}\]
3. 小数定标标准化
\[x' = \frac{x}{10^j}\] 其中\(j\)是使最大绝对值小于1的最小整数。通过移动小数点进行标准化,计算简单。
2. Z-score标准化(标准差标准化)
\[x' = \frac{x - \mu}{\sigma}\]
4. Robust标准化(稳健标准化)
\[x' = \frac{x - \text{median}(x)}{\text{IQR}(x)}\]
其中median是中位数,IQR是四分位距(Q3-Q1)。对异常值不敏感,适用于包含异常值的数据。
Min-Max 归一化
| pm25 | pm10 | co | |
|---|---|---|---|
| 0 | 0.081428 | 0.019635 | 0.000300 |
| 1 | 0.082543 | 0.019975 | 0.000274 |
| 2 | 0.117122 | 0.021223 | 0.000222 |
| 3 | 0.065811 | 0.016797 | 0.000183 |
| 4 | 0.067485 | 0.016116 | 0.000209 |
或使用 scikit-learn 中的函数
array([[8.14277747e-02, 1.96345477e-02, 2.99967395e-04],
[8.25432236e-02, 1.99750312e-02, 2.73883274e-04],
[1.17122142e-01, 2.12234707e-02, 2.21715031e-04],
...,
[1.84049080e-02, 8.51208716e-03, 6.52103032e-05],
[1.11544897e-02, 4.76676881e-03, 6.52103032e-05],
[2.90016732e-02, 8.17160368e-03, 1.17378546e-04]])Z-score 标准化
| pm25 | pm10 | co | |
|---|---|---|---|
| 0 | 2.466409 | 1.375130 | 0.104391 |
| 1 | 2.515985 | 1.419904 | 0.087549 |
| 2 | 4.052852 | 1.584075 | 0.053864 |
| 3 | 1.772340 | 1.002014 | 0.028600 |
| 4 | 1.846704 | 0.912466 | 0.045442 |
或使用 scikit-learn 中的函数
array([[ 2.46641086, 1.37513125, 0.10439155],
[ 2.51598725, 1.41990518, 0.08754893],
[ 4.05285551, 1.58407627, 0.05386369],
...,
[-0.33465547, -0.08748389, -0.04719202],
[-0.65690204, -0.57999715, -0.04719202],
[ 0.13632028, -0.13225782, -0.01350678]])稳健标准化
| pm25 | pm10 | co | |
|---|---|---|---|
| 0 | 3.055556 | 1.770492 | 2.8 |
| 1 | 3.111111 | 1.819672 | 2.4 |
| 2 | 4.833333 | 2.000000 | 1.6 |
| 3 | 2.277778 | 1.360656 | 1.0 |
| 4 | 2.361111 | 1.262295 | 1.4 |
或使用 scikit-learn 中的函数
函数参数说明
min()/max(): 计算最小值/最大值。mean(): 计算均值。std(): 计算标准差。median(): 计算中位数。quantile(): 计算分位数,参数q指定分位点(0-1之间)。np.ceil(): 向上取整。np.log10(): 计算以10为底的对数。MinMaxScaler(): scikit-learn的Min-Max归一化器,fit_transform()同时拟合参数并转换数据。StandardScaler(): scikit-learn的Z-score标准化器。RobustScaler(): scikit-learn的稳健标准化器。
应用场景建议
- Min-Max归一化: 当数据分布范围已知且无极端异常值时使用,如图像处理、神经网络输入。
- Z-score标准化: 当数据近似正态分布时使用,如回归分析、聚类分析。
- Robust标准化: 当数据包含异常值时使用,如金融数据、传感器数据。
- 小数定标标准化: 当需要简单快速标准化时使用,计算复杂度低。
缺失值处理
实际数据中经常存在缺失值,需要识别、分析和处理缺失值,以保证数据分析的可靠性。
识别缺失值
各列缺失值数量:
rank 4868
dtype: int64可视化缺失值分布
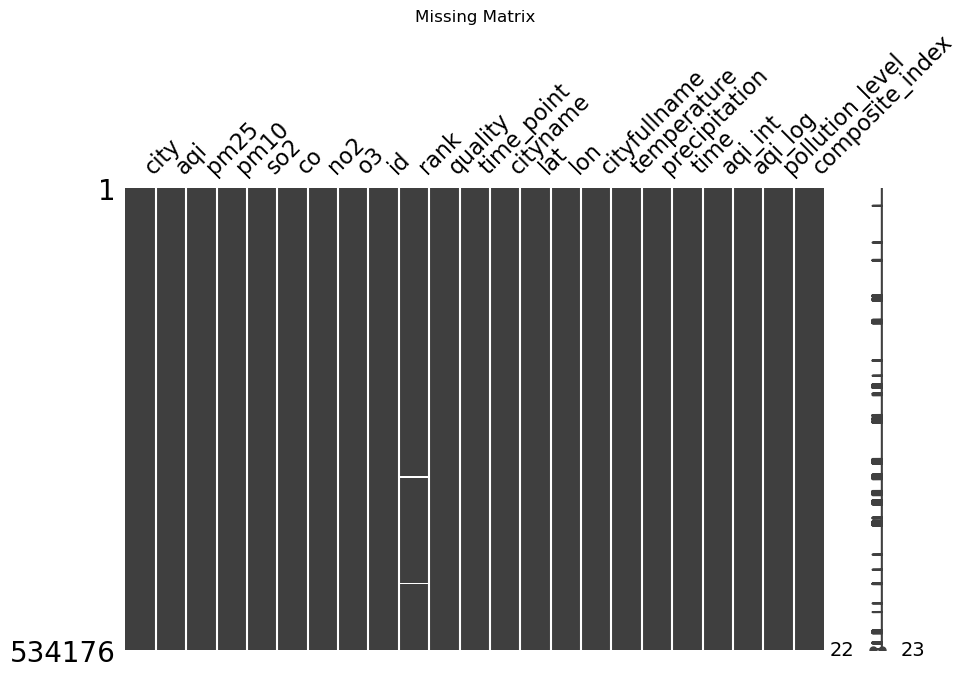
处理缺失值
常见处理方法包括删除、插补(均值、中位数、众数、模型预测等)。
删除
原始数据行数: 534176
删除所有缺失行后行数: 529308
只删除pm25缺失行后行数: 534176插补
均值插补
分组均值插补
aqi_group_imputed = aqi_data.copy()
if 'cityname' in aqi_group_imputed.columns:
numeric_cols = aqi_group_imputed.select_dtypes(include=[np.number]).columns
for col in numeric_cols:
if aqi_group_imputed[col].isnull().any():
aqi_group_imputed[col] = aqi_group_imputed.groupby('cityname')[col].transform(
lambda x: x.fillna(x.mean())
)向前/向后填充
对于时间序列数据,可以使用前后值进行填充。
# 按城市分组,对每个污染物进行向前填充
aqi_filled = aqi_data.copy()
# 确保数据按时间排序
if 'time_point' in aqi_filled.columns and 'cityname' in aqi_filled.columns:
aqi_filled = aqi_filled.sort_values(['cityname', 'time_point'])
# 向前填充(使用前一个非空值)
fill_cols = ['pm25', 'pm10', 'so2', 'co', 'no2', 'o3']
for col in fill_cols:
if col in aqi_filled.columns:
aqi_filled[col] = aqi_filled\
.groupby('cityname')[col]\
.ffill()函数参数说明
isnull(): 检查缺失值,返回布尔DataFrame。sum(): 对布尔值求和,统计True(缺失)的数量。dropna(): 删除包含缺失值的行,subset参数指定只检查特定列。fillna(): 填充缺失值,参数为填充值或填充方法(如mean()、ffill、bfill)。groupby(): 按指定列分组,transform()对每个组应用函数并返回与原始数据相同形状的结果。ffill(): 向前填充,使用前一个非缺失值填充当前缺失值。
数据连接
数据连接是将不同数据源的信息合并在一起的操作。
两个表之间数据的对应关系有几种
- 一对一(1:1)
- 一对多(1:n)
- 多对一(n:1)
- 多对多(n:m)
需要选择合适的方法进行连接。
连接类型
常见连接类型包括内连接、左连接、右连接和外连接。
| 连接类型 | 保留的行 | 缺失匹配的处理 | 结果行数特征 |
|---|---|---|---|
| 内连接 | 只保留两个表中键都匹配的行 | 无缺失 | ≤ 左表行数,也 ≤ 右表行数 |
| 左连接 | 保留左表的全部行,右表只追加匹配的行 | 左表有但右表无匹配的列填充为 NaN(或 None) |
≥ 左表行数(因为左表一行可能匹配右表多行) |
| 右连接 | 保留右表的全部行,左表只追加匹配的行 | 右表有但左表无匹配的列填充为 NaN(或 None) |
≥ 右表行数 |
| 外连接 | 左表和右表的全部行 | 任意一方无匹配 → 对方列填充 NaN |
≥ max(左表, 右表),≤ 左表+右表 |
内连接(inner join)
只保留两个数据集中都存在的观测。
内连接结果形状: (534176, 19)
连接后列名: ['cityname', 'time_point', 'aqi', 'pm25', 'pm10', 'so2', 'co', 'no2', 'o3', 'rank', 'temperature', 'precipitation', 'composite_index', 'lat', 'lon', 'gdp', 'pop', 'area', 'id']左连接(left join)
保留左边数据集的所有观测,右边匹配不到的用NaN填充。
Tip
如果左边一个键对应右边多个行, pandas 会保留右边所有行。但其他软件不一定。
左连接结果形状: (534176, 19)
左连接示例(显示匹配情况):
cityname lon lat
0 长沙 112.967222 28.211223
1 长沙 112.967222 28.211223
2 长沙 112.967222 28.211223
3 长沙 112.967222 28.211223
4 长沙 112.967222 28.211223
5 长沙 112.967222 28.211223
6 长沙 112.967222 28.211223
7 长沙 112.967222 28.211223
8 长沙 112.967222 28.211223
9 长沙 112.967222 28.211223右连接(right join)
保留右边数据集的所有观测,左边匹配不到的用NaN填充。
右连接结果形状: (534234, 16)
右连接示例(显示匹配情况):
cityname lon lat
0 阿坝州 102.22049 31.901829
1 阿坝州 102.22049 31.901829
2 阿坝州 102.22049 31.901829
3 阿坝州 102.22049 31.901829
4 阿坝州 102.22049 31.901829
5 阿坝州 102.22049 31.901829
6 阿坝州 102.22049 31.901829
7 阿坝州 102.22049 31.901829
8 阿坝州 102.22049 31.901829
9 阿坝州 102.22049 31.901829外连接(outer join)
保留两个数据集的所有观测。
外连接结果形状: (534234, 19)
外连接中来自city_data但不在aqi_data中的城市:
<StringArray>
['万宁', '东方', '临安', '临高', '义乌', '乐东', '乳山', '五指山', '伊春', '保亭']
Length: 10, dtype: str多连接键
连接键可以是单个变量或多个变量组合。确保键的类型一致(如字符与字符,数值与数值)。
| cityname | time_point | aqi | pm25 | pm10 | so2 | co | no2 | o3 | rank | month | temperature | precipitation | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 长沙 | 2014-01-01 | 195 | 146 | 173 | 72 | 2.3 | 107 | 47 | 169.0 | 1 | 8.040340 | 0.007594 |
| 1 | 长沙 | 2014-01-02 | 197 | 148 | 176 | 70 | 2.1 | 113 | 41 | 147.0 | 1 | 9.650864 | 0.004159 |
| 2 | 长沙 | 2014-01-03 | 260 | 210 | 187 | 71 | 1.7 | 83 | 25 | 171.0 | 1 | 10.266930 | 0.007058 |
| 3 | 长沙 | 2014-01-04 | 154 | 118 | 148 | 56 | 1.4 | 83 | 65 | 127.0 | 1 | 8.254520 | 0.002372 |
| 4 | 长沙 | 2014-01-05 | 158 | 121 | 142 | 50 | 1.6 | 87 | 65 | 103.0 | 1 | 8.406674 | 0.077707 |
基础数据分析
基础数据分析包括汇总统计、回归分析、方差分析等,帮助我们理解数据分布和变量间关系。
汇总统计
对数据进行描述性统计,包括均值、中位数、标准差、分位数等。
均值(Mean): 所有观测值的算术平均值。当数据分布对称且无极端值时使用 \[\bar{x} = \frac{1}{n}\sum_{i=1}^{n} x_i\]
df['col'].mean() 或 np.mean(array)
标准差(Standard Deviation): 数据离散程度的度量,表示数据点与均值的平均距离。衡量数据的波动性、风险等。 \[s = \sqrt{\frac{1}{n-1}\sum_{i=1}^{n}(x_i - \bar{x})^2}\]
df['col'].std(ddof=1) 或 np.std(array, ddof=1)
方差(Variance): 标准差的平方,表示数据离散程度的平方度量 \[s^2 = \frac{1}{n-1}\sum_{i=1}^{n}(x_i - \bar{x})^2\]
df['col'].var(ddof=1) 或 np.var(array, ddof=1)
中位数(Median): 将数据按大小排序后位于中间位置的值。当数据包含异常值或分布偏斜时使用。
df['col'].median() 或 np.median(array)
分位数(Quantile): 将数据按大小排序后等分的临界点
- 计算
- 将数据排序:\(x_{(1)} \leq x_{(2)} \leq \cdots \leq x_{(n)}\)
- 位置计算:\(位置 = 1 + (n-1) \times p\%\)
- 如果位置是整数,取对应值;如果是小数,使用线性插值
df['col'].quantile(0.25)(Q1), df['col'].quantile(0.5)(中位数), df['col'].quantile(0.75)(Q3)
四分位距(Interquartile Range, IQR): 第三四分位数与第一四分位数之差 \[IQR = Q3 - Q1\]
- 应用: 异常值检测(通常将小于\(Q1 - 1.5 \times IQR\)或大于\(Q3 + 1.5 \times IQR\)的值视为异常值)
df['col'].quantile(0.75) - df['col'].quantile(0.25)
偏度(Skewness): 数据分布不对称程度的度量 \[g_1 = \frac{\frac{1}{n}\sum_{i=1}^{n}(x_i - \bar{x})^3}{\left(\frac{1}{n}\sum_{i=1}^{n}(x_i - \bar{x})^2\right)^{3/2}}\]
- 意义:
- 偏度 > 0:右偏(正偏),均值 > 中位数
- 偏度 < 0:左偏(负偏),均值 < 中位数
- 偏度 ≈ 0:分布对称
- 应用: 检验数据分布的正态性
df['col'].skew() 或 scipy.stats.skew(array)
众数(Mode): 数据中出现次数最多的值
df['col'].mode()[0] 或 stats.mode(array)
单变量统计
分组汇总统计
| cityname | mean_aqi | median_aqi | sd_aqi | days | |
|---|---|---|---|---|---|
| 60 | 和田地区 | 176.027140 | 131.0 | 138.693014 | 1437 |
| 67 | 喀什地区 | 169.638947 | 133.0 | 119.155084 | 1443 |
| 28 | 保定 | 140.108093 | 120.0 | 80.835950 | 1841 |
| 272 | 邢台 | 138.219446 | 117.0 | 81.173437 | 1841 |
| 225 | 石家庄 | 135.435256 | 112.0 | 84.017301 | 1838 |
| ... | ... | ... | ... | ... | ... |
| 322 | 黔西南州 | 43.258065 | 41.0 | 15.911391 | 1457 |
| 186 | 海口 | 43.250675 | 38.0 | 20.994899 | 1851 |
| 16 | 丽江 | 42.597804 | 41.0 | 11.852409 | 1457 |
| 267 | 迪庆州 | 39.720467 | 38.0 | 12.356759 | 1456 |
| 1 | 三亚 | 38.243139 | 33.0 | 17.971288 | 1822 |
325 rows × 5 columns
多变量交叉统计
| month | cityname | mean_aqi | |
|---|---|---|---|
| 0 | 1 | 七台河 | 96.822581 |
| 1 | 1 | 三亚 | 50.051613 |
| 2 | 1 | 三明 | 53.508065 |
| 3 | 1 | 三门峡 | 146.851613 |
| 4 | 1 | 上海 | 96.270968 |
| ... | ... | ... | ... |
| 3895 | 12 | 黔东南州 | 64.958678 |
| 3896 | 12 | 黔南州 | 63.850000 |
| 3897 | 12 | 黔西南州 | 47.049587 |
| 3898 | 12 | 齐齐哈尔 | 80.447368 |
| 3899 | 12 | 龙岩 | 49.421488 |
3900 rows × 3 columns
回归分析
回归分析用于研究变量之间的因果关系。多元线性回归分析多个自变量与一个因变量之间的线性关系。
回归分析理论基础
1. 数学模型
多元线性回归模型的一般形式为: \[y_i = \beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \cdots + \beta_p x_{ip} + \varepsilon_i\] 其中:
- \(y_i\):第\(i\)个观测的因变量(响应变量)
- \(x_{i1}, x_{i2}, \ldots, x_{ip}\):第\(i\)个观测的\(p\)个自变量(解释变量)
- \(\beta_0\):截距项(常数项)
- \(\beta_1, \beta_2, \ldots, \beta_p\):回归系数,表示各自变量对因变量的边际影响
- \(\varepsilon_i\):随机误差项,满足\(\varepsilon_i \sim N(0, \sigma^2)\)
矩阵形式:
\(Y = X\beta + \varepsilon\)
其中\(Y\)为\(n \times 1\)的因变量向量,\(X\)为\(n \times (p+1)\)的设计矩阵,\(\beta\)为\((p+1) \times 1\)的系数向量。
2. 参数估计(最小二乘法)
回归系数的估计通过最小化残差平方和(RSS)得到: \[\hat{\beta} = \arg\min_{\beta} \sum_{i=1}^n (y_i - \beta_0 - \beta_1 x_{i1} - \cdots - \beta_p x_{ip})^2\] 矩阵形式的解为:\(\hat{\beta} = (X^T X)^{-1} X^T Y\)
3. 回归分析的前提假设(经典线性回归假设)
- 线性关系:自变量与因变量之间存在线性关系
- 独立性:观测值之间相互独立
- 同方差性:误差项的方差恒定(homoscedasticity)
- 正态性:误差项服从正态分布
- 无多重共线性:自变量之间不存在高度相关性
- 无测量误差:自变量测量准确无误
- 无异常值:数据中不存在极端异常值
4. 回归结果的关键统计量
- R-squared(\(R^2\)):模型解释的方差比例,\(R^2 = 1 - \frac{SS_{res}}{SS_{tot}}\),范围[0,1],越大越好
- Adjusted R-squared:调整的\(R^2\),考虑自变量个数对\(R^2\)的影响
- F-statistic:整体模型显著性检验,检验所有系数是否同时为0
- Coefficients:回归系数\(\hat{\beta}_j\),表示\(x_j\)每变化1单位,\(y\)的平均变化量
- t-statistic:单个系数显著性检验,\(t = \frac{\hat{\beta}_j}{SE(\hat{\beta}_j)}\)
- p-value:系数显著性的概率,通常\(p < 0.05\)认为显著
- 标准误(SE):系数估计的标准误差,衡量估计精度
- 置信区间:系数的95%置信区间
5. 模型诊断与检验
- 残差分析:检查残差是否随机分布、满足同方差性和正态性
- 多重共线性诊断:方差膨胀因子(VIF),通常VIF > 10表示严重共线性
- 异方差性检验:Breusch-Pagan检验、White检验
- 正态性检验:残差的Q-Q图、Shapiro-Wilk检验
- 异常值检测:Cook距离、杠杆值、学生化残差
6. 注意事项
- 样本量要求:通常每个自变量需要10-15个观测值
- 变量选择:避免过度拟合(变量太多)和欠拟合(变量太少)
- 数据预处理:需要进行缺失值处理、异常值处理、变量转换等
- 模型验证:使用交叉验证、训练集-测试集分割验证模型泛化能力
- 结果报告:应报告系数、标准误、\(p\)值、\(R^2\)、样本量等关键信息
多元线性回归示例
Warning
此处仅作演示,不进行真正的数据分析。
数据预处理
在开始前,一般先检查通过相关性矩阵检查数据分布和变量之间的相关性。如果有非正态分布的变量,要注意将其正态化。
数据预处理
此处演示三种正态化方法:
- 取对数:用于纠正右偏数据
- Yeo-Johnson 变换:可用于有正有负的数据
- Box-Cox 变换:只能用于正数
pm25_tem_pre_norm = pm25_tem_pre.copy()
pm25_tem_pre_norm['pm25'] = np.log(pm25_tem_pre_norm['pm25'])
pm25_tem_pre_norm['temperature'] = stats.yeojohnson(pm25_tem_pre_norm['temperature'])[0]
pm25_tem_pre_norm['precipitation'] = stats.boxcox(pm25_tem_pre_norm['precipitation'])[0]
pm25_tem_pre_norm[['temperature', 'precipitation']] = StandardScaler().fit_transform(pm25_tem_pre_norm[['temperature', 'precipitation']])
fig, axis = plt.subplots(3, 3)
for i in range(3):
for j in range(3):
if i == j:
axis[i, j].hist(pm25_tem_pre_norm.iloc[:, i], bins=30)
axis[i, j].set_yticks([])
elif i > j:
axis[i, j].scatter(pm25_tem_pre_norm.iloc[:, i], pm25_tem_pre_norm.iloc[:, j], s=0.1)
else:
axis[i, j].text(0.5, 0.5, '{:.2f}'.format(np.corrcoef(pm25_tem_pre_norm.iloc[:, i], pm25_tem_pre_norm.iloc[:, j])[0][1]))
if i != 2:
axis[i, j].set_xticks([])
if j != 0:
axis[i, j].set_yticks([])
plt.show()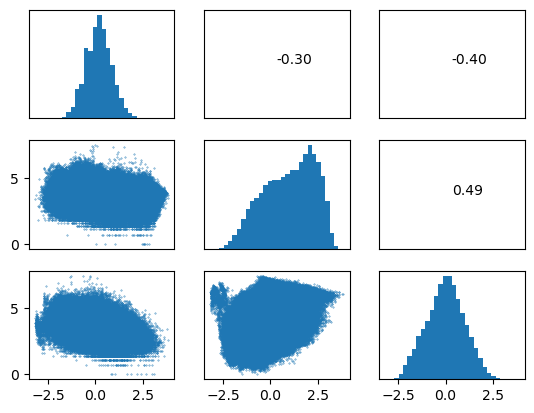
构建回归分析模型
statsmodels 包提供了构建回归分析模型的工具。输入因变量和自变量,即可得到模型结果。
Tip
注意对自变量使用 sm.add_constant 函数增加一个截距项。
构建回归分析模型
| Dep. Variable: | pm25 | R-squared: | 0.175 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.175 |
| Method: | Least Squares | F-statistic: | 5.570e+04 |
| Date: | Mon, 06 Apr 2026 | Prob (F-statistic): | 0.00 |
| Time: | 14:38:50 | Log-Likelihood: | -5.2384e+05 |
| No. Observations: | 526481 | AIC: | 1.048e+06 |
| Df Residuals: | 526478 | BIC: | 1.048e+06 |
| Df Model: | 2 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 3.5877 | 0.001 | 3977.660 | 0.000 | 3.586 | 3.589 |
| temperature | -0.0988 | 0.001 | -95.745 | 0.000 | -0.101 | -0.097 |
| precipitation | -0.2403 | 0.001 | -232.793 | 0.000 | -0.242 | -0.238 |
| Omnibus: | 688.451 | Durbin-Watson: | 0.554 |
|---|---|---|---|
| Prob(Omnibus): | 0.000 | Jarque-Bera (JB): | 714.098 |
| Skew: | -0.073 | Prob(JB): | 8.62e-156 |
| Kurtosis: | 3.107 | Cond. No. | 1.70 |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
回归诊断
对于回归分析的诊断通常从残差着手。通常模型要求残差具有
- 正态性
- 同方差性
- 无偏性
首先获取残差值和拟合值。
通过以下几幅图进行分析
- 残差图
- Q-Q 图
- 残差直方图
- 观测-预测图
残差图
残差图是指以残差为纵坐标,以任何其他指定的量为横坐标的散点图。残差不应该成片的很高或很低,而是在拟合值的范围内,残差应该以0为中心。
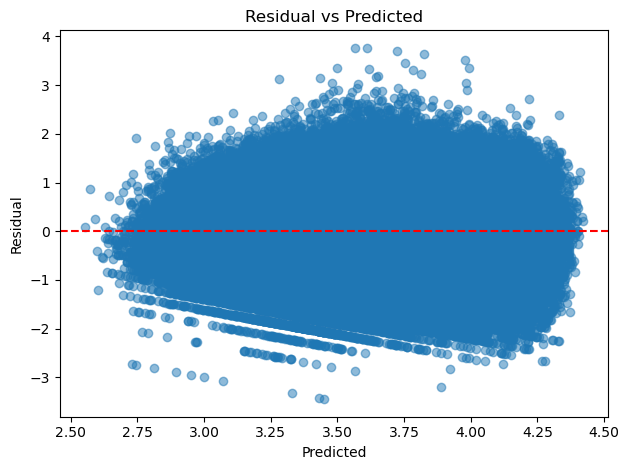
Q-Q图
Q-Q 是一种用于比较两个概率分布是否相似的统计图形工具。通过绘制残差的各分位数和标准正态分布的各分位数,可以看到残差是否服从正态分布。
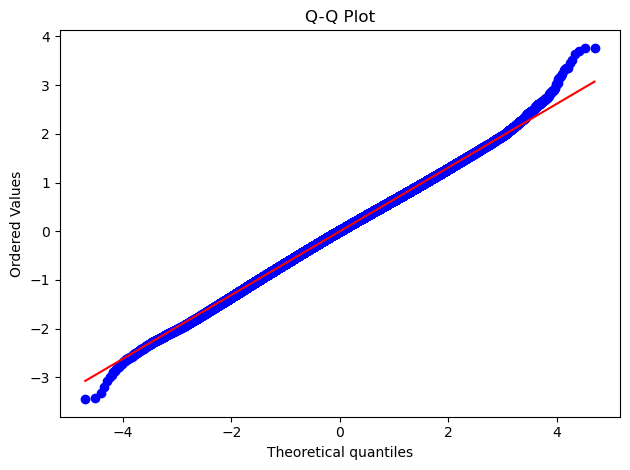
残差直方图
残差直方图也是一种判断残差是否正态分布的方法。
plt.hist(model_aqi_res, bins=30, edgecolor='black', alpha=0.7, density=True)
# 添加正态分布曲线参考
x = np.linspace(model_aqi_res.min(), model_aqi_res.max(), 100)
plt.plot(x, stats.norm.pdf(x, model_aqi_res.mean(), model_aqi_res.std()), 'r-', lw=2)
plt.xlabel('Residual')
plt.ylabel('Density')
plt.title('Histogram of Residuals')
plt.tight_layout()
plt.show()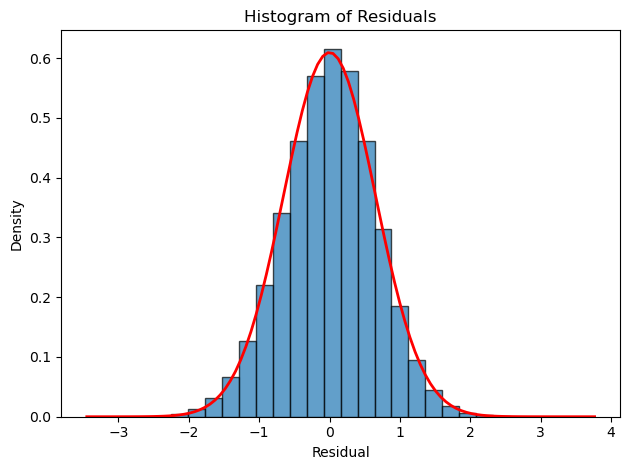
拟合值 vs 观测值
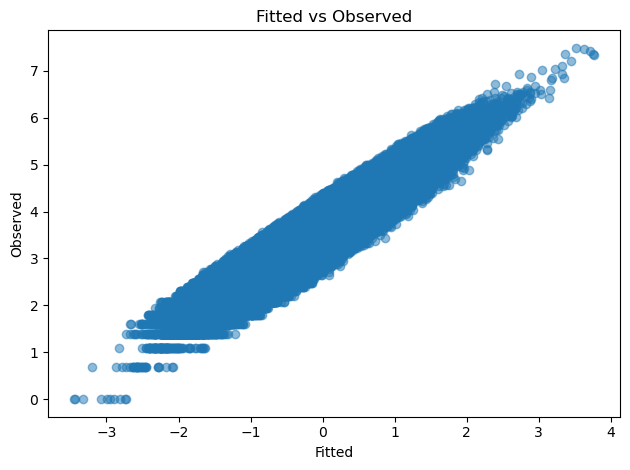
统计诊断
除了对残差进行绘图分析之外,还可以进行一些统计诊断,分析模型的建模效果。
通常进行以下检验:
- 异方差检验
- 正态性检验
- 多重共线性检验
- 异常值检测
异方差性检验(Breusch-Pagan检验)
from statsmodels.stats.diagnostic import het_breuschpagan
bp_test = het_breuschpagan(model_aqi_res, model_aqi.model.exog, robust=True)
print(f"Breusch-Pagan异方差检验:")
print(f" LM统计量: {bp_test[0]:.4f}, p值: {bp_test[1]:.4f}")
print(f" F统计量: {bp_test[2]:.4f}, p值: {bp_test[3]:.4f}")
if bp_test[1] < 0.05:
print(" → 拒绝同方差原假设,存在异方差问题")
else:
print(" → 不能拒绝同方差原假设")Breusch-Pagan异方差检验:
LM统计量: 14630.4075, p值: 0.0000
F统计量: 7524.2540, p值: 0.0000
→ 拒绝同方差原假设,存在异方差问题正态性检验(Shapiro-Wilk检验)
Shapiro-Wilk正态性检验:
统计量: 0.9988, p值: 0.0009
→ 拒绝正态性原假设,残差不服从正态分布多重共线性诊断(VIF)
from statsmodels.stats.outliers_influence import variance_inflation_factor
print(f"\n方差膨胀因子(VIF)检验:")
vif_data = pd.DataFrame()
vif_data["Variable"] = pm25_tem_pre_norm.columns[1:]
vif_data["VIF"] = [variance_inflation_factor(pm25_tem_pre_norm.values[:, 1:], i)
for i in range(pm25_tem_pre_norm.values[:, 1:].shape[1])]
print(vif_data)
high_vif = vif_data[vif_data["VIF"] > 10]
if len(high_vif) > 0:
print(f" → 警告: {len(high_vif)}个变量VIF > 10,存在多重共线性问题")
else:
print(" → VIF值正常,无严重多重共线性")
方差膨胀因子(VIF)检验:
Variable VIF
0 temperature 1.309916
1 precipitation 1.309916
→ VIF值正常,无严重多重共线性异常值检测(Cook距离)
print(f"\n异常值检测(Cook距离):")
cooks_d = model_aqi.get_influence().cooks_distance[0]
high_influence = np.where(cooks_d > 4 / len(cooks_d))[0] # Cook距离 > 4/n
if len(high_influence) > 0:
print(f" 发现{len(high_influence)}个高影响点(Cook距离 > 4/n)")
print(f" 最大Cook距离: {cooks_d.max():.4f}")
# 显示前10个高影响点
print(f" 前10个高影响点索引: {high_influence[:10]}")
else:
print(" 未发现高影响点")
异常值检测(Cook距离):
发现26645个高影响点(Cook距离 > 4/n)
最大Cook距离: 0.0001
前10个高影响点索引: [ 2 6 8 15 16 23 24 25 27 28]方差分析
方差分析(ANOVA)的核心思想是比较不同来源的变异,从而判断分组变量是否对结果(如体重)产生了显著影响。
先对空气质量数据进行处理,提取出季节、年份的信息。
seasons = ['Spring', 'Summer', "Fall", "Winter"]
aqi_season = aqi_data[['aqi', 'cityname', 'time_point']].groupby('time_point').agg({
'aqi': 'mean'
}).reset_index()
aqi_season['year'] = pd.to_datetime(aqi_season['time_point']).dt.year
aqi_season['month'] = pd.to_datetime(aqi_season['time_point']).dt.month
aqi_season['season'] = np.select([
(aqi_season['month'] >= 3) & (aqi_season['month'] <= 5),
(aqi_season['month'] >= 6) & (aqi_season['month'] <= 8),
(aqi_season['month'] >= 9) & (aqi_season['month'] <= 11),
(aqi_season['month'] >= 12) | (aqi_season['month'] <= 2),
], seasons, default='Unknown')
aqi_season = aqi_season[aqi_season['season'] != 'Unknown']
aqi_season方差分析
| time_point | aqi | year | month | season | |
|---|---|---|---|---|---|
| 0 | 2013-12-01 | 157.055556 | 2013 | 12 | Winter |
| 1 | 2013-12-02 | 176.259843 | 2013 | 12 | Winter |
| 2 | 2013-12-03 | 191.551181 | 2013 | 12 | Winter |
| 3 | 2013-12-04 | 183.436508 | 2013 | 12 | Winter |
| 4 | 2013-12-05 | 171.842520 | 2013 | 12 | Winter |
| ... | ... | ... | ... | ... | ... |
| 1847 | 2018-12-23 | 69.236923 | 2018 | 12 | Winter |
| 1848 | 2018-12-24 | 72.209231 | 2018 | 12 | Winter |
| 1849 | 2018-12-25 | 78.160000 | 2018 | 12 | Winter |
| 1850 | 2018-12-26 | 63.227692 | 2018 | 12 | Winter |
| 1851 | 2018-12-27 | 59.526154 | 2018 | 12 | Winter |
1852 rows × 5 columns
单因素方差分析
研究单个因素是否对空气质量产生了显著影响。
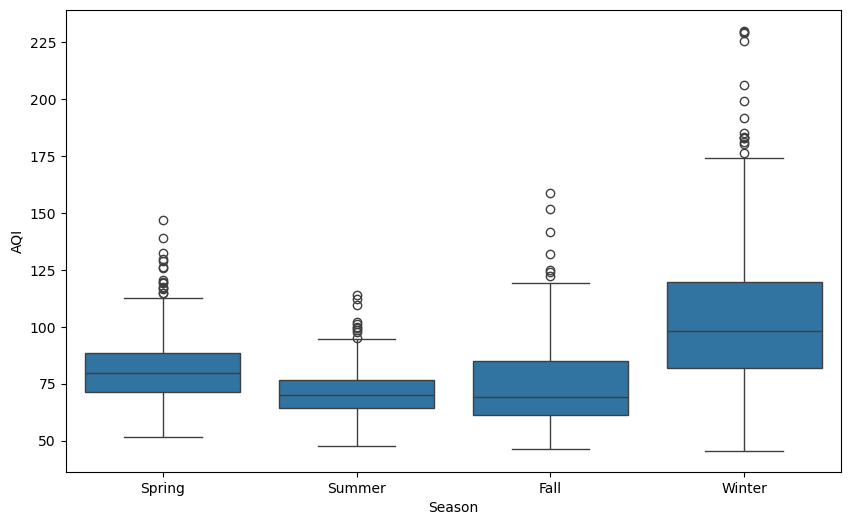
双因素方差分析
总结
本章介绍了基础数据处理的核心技术:数据转换、缺失值处理、数据连接和基础数据分析。通过实际空气质量数据案例,演示了各类操作的Python实现方法。掌握这些基础技能是进行更复杂空间分析的前提。