| cityname | time_point | aqi | pm25 | pm10 | so2 | co | no2 | o3 | rank | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 长沙 | 2014-01-01 | 195 | 146 | 173 | 72 | 2.3 | 107 | 47 | 169.0 |
| 1 | 长沙 | 2014-01-02 | 197 | 148 | 176 | 70 | 2.1 | 113 | 41 | 147.0 |
| 2 | 长沙 | 2014-01-03 | 260 | 210 | 187 | 71 | 1.7 | 83 | 25 | 171.0 |
| 3 | 长沙 | 2014-01-04 | 154 | 118 | 148 | 56 | 1.4 | 83 | 65 | 127.0 |
| 4 | 长沙 | 2014-01-05 | 158 | 121 | 142 | 50 | 1.6 | 87 | 65 | 103.0 |
基础数据读写与可视化
GIS程序与设计
本章将介绍使用 Python 进行数据分析的基础操作,包括数据文件的读写、数据查询和数据可视化。我们将使用 pandas 库进行数据处理,使用 matplotlib 和 seaborn 进行数据可视化。
基础数据文件读写
常见文件格式
在数据分析中,我们常遇到以下几种数据文件格式:
- CSV(Comma-Separated Values):以逗号分隔的文本文件,是最常用的数据交换格式。
- Excel:微软的电子表格格式,可以包含多个工作表。
- JSON(JavaScript Object Notation):轻量级的数据交换格式,易于人阅读和编写。
- Parquet:列式存储格式,适合大规模数据分析,具有高效的压缩和编码。
- Feather:一种快速、轻量级的二进制格式,用于存储数据框,读写速度极快。
- HDF5:适用于存储大规模科学数据的层次化格式。
Pandas 已经封装了大量工具函数,可以轻松地从文件中读取数据。
读写文件
在开始之前,请确保已安装 pandas 和 openpyxl(用于读写 Excel 文件)。可以使用以下命令安装:
CSV 格式
CSV(Comma-Separated Values,逗号分隔值)是一种纯文本表格数据格式,每一行表示一条记录,字段之间通常用逗号分隔。
优点是:
- 通用性强:几乎所有数据分析工具和数据库都支持。
- 可读性好:可直接用文本编辑器查看。
- 结构简单:通常第一行为列名,后续行为数据。
缺点是:
- 缺少类型信息,只保存数据
- 缺少约束
- 分隔符容易与字段值中出现的标点符号混淆
读取 CSV 文件
| cityname | lat | lon | gdp | pop | area | id | |
|---|---|---|---|---|---|---|---|
| 0 | 阿坝州 | 31.901829 | 102.220490 | NaN | NaN | NaN | 1 |
| 1 | 安康 | 32.700697 | 109.026587 | NaN | NaN | NaN | 2 |
| 2 | 阿克苏地区 | 41.164593 | 80.261251 | NaN | NaN | NaN | 3 |
| 3 | 阿里地区 | 30.401208 | 81.098638 | NaN | NaN | NaN | 4 |
| 4 | 阿拉善盟 | 38.836591 | 105.685013 | NaN | NaN | NaN | 5 |
read_csv 函数有很多参数可以控制读取过程,例如:
sep:指定分隔符,默认为逗号。header:指定表头行,默认为 0(第一行作为列名)。encoding:指定文件编码,如'utf-8'、'gbk'等。na_values:指定哪些值应被视为缺失值。
写入 CSV 文件
函数常用参数及作用
| 参数 | 作用 | 常见取值示例 |
|---|---|---|
index |
是否写入行索引 | False(常用) |
header |
是否写列名 | True/False |
sep |
字段分隔符 | ','(默认)、'\t'(TSV) |
quotechar |
文本引用符号 | '"' |
quoting |
引号策略(csv 模块常量) |
csv.QUOTE_MINIMAL 等 |
lineterminator |
行结束符 | '\n'、'\r\n' |
na_rep |
缺失值的输出文本 | ''、'NA'、'NULL' |
float_format |
浮点数格式 | '%.2f' |
errors |
编码错误处理方式 | 'strict'、'ignore'、'replace' |
Excel 格式
Excel 是一种电子表格文件格式(常见扩展名为 .xlsx),支持多工作表、单元格格式、公式、图表和数据透视等功能,适合日常数据整理与报告展示。一个 Excel 可以包含多个工作表,每个工作表如果都按关系数据排列,那么可以存储多个数据。
优点:
- 易用性高:界面直观,适合非程序员操作
- 功能丰富:支持公式、图表、筛选、透视表
- 可读性好:便于人工查看和编辑
- 多表管理:一个文件可存放多个相关数据表
缺点:
- 性能有限:处理超大数据时速度慢、占内存高
- 自动化较弱:批量处理和流程化不如代码工具高效
- 格式依赖强:样式、合并单元格等会增加数据处理难度
读取 Excel 文件
在读取时,需要指定工作表。
| cityname | time_point | aqi | pm25 | pm10 | so2 | co | no2 | o3 | rank | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 长沙 | 2014-01-01 | 195 | 146 | 173 | 72 | 2.3 | 107 | 47 | 169.0 |
| 1 | 长沙 | 2014-01-02 | 197 | 148 | 176 | 70 | 2.1 | 113 | 41 | 147.0 |
| 2 | 长沙 | 2014-01-03 | 260 | 210 | 187 | 71 | 1.7 | 83 | 25 | 171.0 |
| 3 | 长沙 | 2014-01-04 | 154 | 118 | 148 | 56 | 1.4 | 83 | 65 | 127.0 |
| 4 | 长沙 | 2014-01-05 | 158 | 121 | 142 | 50 | 1.6 | 87 | 65 | 103.0 |
| cityname | time_point | aqi | pm25 | pm10 | so2 | co | no2 | o3 | rank | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 长沙 | 2014-01-01 | 195 | 146 | 173 | 72 | 2.3 | 107 | 47 | 169.0 |
| 1 | 长沙 | 2014-01-02 | 197 | 148 | 176 | 70 | 2.1 | 113 | 41 | 147.0 |
| 2 | 长沙 | 2014-01-03 | 260 | 210 | 187 | 71 | 1.7 | 83 | 25 | 171.0 |
| 3 | 长沙 | 2014-01-04 | 154 | 118 | 148 | 56 | 1.4 | 83 | 65 | 127.0 |
| 4 | 长沙 | 2014-01-05 | 158 | 121 | 142 | 50 | 1.6 | 87 | 65 | 103.0 |
也可以将 sheet_name 设置为 None 以读取所有工作表,返回一个字典,键为工作表名,值为 DataFrame。
写入 Excel 文件
写入时,同样也需要指定工作表。
JSON 格式
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,使用文本存储结构化数据。它易读、易写、跨语言支持广,常用于接口传输、配置文件和日志数据。
JSON 基本规范
| 规范项 | 说明 | 示例 |
|---|---|---|
| 顶层结构 | 必须是对象或数组 | {...} / [...] |
| 键名 | 对象的键必须使用双引号包裹 | {"city": "南京"} |
| 字符串 | 必须使用双引号(不能用单引号) | "quality": "良" |
| 数值 | 支持整数和浮点数,不支持 NaN/Infinity |
"aqi": 85 |
| 布尔与空值 | 使用小写 true、false、null |
"valid": true |
| 注释 | 标准 JSON 不允许注释 | ❌ // comment |
| 末尾逗号 | 最后一个键值对后不能有逗号 | ❌ {"a":1,} |
| 编码 | 通常使用 UTF-8 | 推荐默认 UTF-8 |
优点:
- 结构清晰、可读性好,便于人工查看
- 跨平台、跨语言支持广,生态成熟
- 适合网络传输与接口数据交换
- 与 Python 的
dict/list映射自然,处理方便
缺点:
- 相比二进制格式(如 Parquet/Feather)体积更大、读写更慢
- 不支持注释、日期等原生类型(日期常需字符串表示)
- 嵌套层级深时解析和维护成本较高
- 对超大规模分析场景不够高效(压缩与列式查询能力较弱)
读取 JSON 文件
如果数据是以 JSON 格式存储的,往往会有两种情况:
- 以标准 JSON 格式存储。此时存在记录顺序、字段顺序两种情况:
- 记录顺序:整个文件是一个数组,数组的每个元素是一个表示记录的对象。
- 列顺序:整个文件是一个对象,对象的每个属性也是一个对象,记录了一个列的所有值,按记录顺序排列。
- 每行是一个标准 JSON 格式字符串,但整体不是。这种被称为行 JSON(
*.jsonl)格式。
pd.read_json 通过参数 lines 控制是否是行JSON格式读取;如果为 False,则通过 orient 控制是按记录顺序(records)还是列顺序(columns)读取。
记录顺序读取
示例
列顺序读取
示例
行 JSON 格式读取
样例
{"cityname":"长沙","time_point":"2014-01-01","aqi":195,"pm25":146,"pm10":173,"so2":72,"co":2.3,"no2":107,"o3":47}
{"cityname":"长沙","time_point":"2014-01-02","aqi":197,"pm25":148,"pm10":176,"so2":70,"co":2.1,"no2":113,"o3":41}
{"cityname":"长沙","time_point":"2014-01-03","aqi":260,"pm25":210,"pm10":187,"so2":71,"co":1.7,"no2":83,"o3":25}嵌套结构
如果 JSON 数据是嵌套结构,可以使用 json_normalize 进行展平
写入 JSON 文件
Parquet 文件
Parquet 文件是一种开源的列式存储文件格式,专为大数据处理场景设计(如 Hadoop、Spark 等)。
核心特点:
- 列式存储:数据按列而非按行组织。查询时只需读取涉及的列,大幅减少 I/O 和内存消耗。
- 高效压缩:同一列数据类型相同,便于使用针对性的压缩算法(如 Snappy、GZip、Zstd)和编码(如字典编码、RLE),压缩比高。
- 嵌套结构支持:原生支持复杂嵌套数据类型(如 JSON-like 的 struct、list、map),无需扁平化。
- Schema 演进:支持添加、删除或修改列,保持向后兼容。
- 自带元数据:文件尾部存储列统计信息(最小值、最大值等)和偏移量,支持谓词下推(跳过不匹配的数据块)和快速剪枝。
一个 Parquet 文件由多个 Row Group(行组)组成,每个 Row Group 包含对应列的 Column Chunk,Column Chunk 内部进一步分为 Page(压缩/编码的最小单元)。
读取 Parquet 文件
写入 Parquet 文件
多文件处理
在实际项目中,数据可能分散在多个文件中,我们需要批量读取并合并。
(534176, 11)可以改写成列表推导式的方式。
数据查询
数据查询是数据分析的核心步骤,包括查看数据属性、筛选感兴趣的行列、以及分组聚合。
属性
读取数据后,我们首先需要了解数据的基本情况。
| aqi | pm25 | pm10 | so2 | co | no2 | o3 | rank | |
|---|---|---|---|---|---|---|---|---|
| count | 534176.000000 | 534176.000000 | 534176.000000 | 534176.000000 | 534176.000000 | 534176.000000 | 534176.000000 | 529308.000000 |
| mean | 80.658974 | 46.500597 | 80.861707 | 22.044118 | 1.060388 | 30.724097 | 89.044527 | 165.694913 |
| std | 49.362288 | 40.341817 | 67.003335 | 24.424131 | 11.874649 | 17.843356 | 43.612983 | 101.878181 |
| min | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.000000 |
| 25% | 50.000000 | 22.000000 | 41.000000 | 9.000000 | 0.700000 | 18.000000 | 58.000000 | 78.000000 |
| 50% | 69.000000 | 36.000000 | 65.000000 | 15.000000 | 0.900000 | 27.000000 | 84.000000 | 158.000000 |
| 75% | 97.000000 | 58.000000 | 102.000000 | 26.000000 | 1.200000 | 40.000000 | 115.000000 | 252.000000 |
| max | 1210.000000 | 1793.000000 | 8811.000000 | 858.000000 | 7667.500000 | 461.000000 | 586.000000 | 368.000000 |
| cityname | time_point | aqi | pm25 | pm10 | so2 | co | no2 | o3 | rank | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 长沙 | 2014-01-01 | 195 | 146 | 173 | 72 | 2.3 | 107 | 47 | 169.0 |
| 1 | 长沙 | 2014-01-02 | 197 | 148 | 176 | 70 | 2.1 | 113 | 41 | 147.0 |
| 2 | 长沙 | 2014-01-03 | 260 | 210 | 187 | 71 | 1.7 | 83 | 25 | 171.0 |
<class 'pandas.DataFrame'>
RangeIndex: 534176 entries, 0 to 534175
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 cityname 534176 non-null str
1 time_point 534176 non-null str
2 aqi 534176 non-null int64
3 pm25 534176 non-null int64
4 pm10 534176 non-null int64
5 so2 534176 non-null int64
6 co 534176 non-null float64
7 no2 534176 non-null int64
8 o3 534176 non-null int64
9 rank 529308 non-null float64
dtypes: float64(2), int64(6), str(2)
memory usage: 40.8 MB筛选
筛选操作允许我们根据条件选择数据的子集。
按列筛选
使用 loc 按标签选择(行标签和列标签)
按条件筛选行
Pandas 提供了多种按条件筛选的方式
- 使用 Python 表达式
- 使用字符串表达式
Tip
在处理字符串时,通常会用到正则表达式对字符串进行处理。
使用 Python 表达式筛选
单条件筛选
| cityname | time_point | aqi | pm25 | pm10 | so2 | co | no2 | o3 | rank | |
|---|---|---|---|---|---|---|---|---|---|---|
| 89930 | 酒泉 | 2017-12-29 | 1137 | 0 | 0 | 11 | 0.9 | 24 | 79 | 220.0 |
| 192743 | 嘉峪关 | 2017-12-29 | 1210 | 0 | 0 | 22 | 0.6 | 20 | 72 | 324.0 |
| 233499 | 金昌 | 2017-12-29 | 1185 | 0 | 0 | 12 | 0.7 | 11 | 67 | 334.0 |
| 403898 | 中卫 | 2017-12-28 | 1090 | 0 | 0 | 38 | 1.7 | 40 | 77 | 286.0 |
| 403930 | 武威 | 2017-12-29 | 1087 | 0 | 0 | 10 | 1.0 | 22 | 70 | 316.0 |
多条件筛选(且)
| cityname | time_point | aqi | pm25 | pm10 | so2 | co | no2 | o3 | rank | |
|---|---|---|---|---|---|---|---|---|---|---|
| 480272 | 南京 | 2013-12-04 | 386 | 336 | 455 | 51 | 2.5 | 130 | 43 | 109.0 |
| 480273 | 南京 | 2013-12-05 | 328 | 278 | 386 | 52 | 2.3 | 110 | 59 | 99.0 |
| 480274 | 南京 | 2013-12-06 | 319 | 269 | 389 | 61 | 2.2 | 92 | 36 | 99.0 |
| 480275 | 南京 | 2013-12-07 | 366 | 316 | 429 | 44 | 2.9 | 95 | 44 | 96.0 |
| 480293 | 南京 | 2013-12-25 | 307 | 257 | 383 | 138 | 2.7 | 136 | 22 | 82.0 |
| 480379 | 南京 | 2014-01-18 | 347 | 297 | 391 | 71 | 2.1 | 79 | 56 | 178.0 |
| 480380 | 南京 | 2014-01-19 | 327 | 277 | 371 | 67 | 2.0 | 88 | 80 | 173.0 |
| 487925 | 南京 | 2017-12-31 | 304 | 0 | 0 | 17 | 2.3 | 89 | 50 | 328.0 |
多条件筛选(或)
| cityname | time_point | aqi | pm25 | pm10 | so2 | co | no2 | o3 | rank | |
|---|---|---|---|---|---|---|---|---|---|---|
| 166281 | 喀什地区 | 2016-03-05 | 500 | 1733 | 8811 | 13 | 1.6 | 22 | 49 | 365.0 |
| 166282 | 喀什地区 | 2016-03-06 | 500 | 1566 | 6568 | 14 | 2.1 | 36 | 34 | 366.0 |
| 166283 | 喀什地区 | 2016-03-07 | 500 | 1793 | 4673 | 17 | 2.8 | 39 | 40 | 365.0 |
| 166284 | 喀什地区 | 2016-03-08 | 500 | 1684 | 3231 | 17 | 2.6 | 39 | 60 | 364.0 |
| 167104 | 喀什地区 | 2016-05-02 | 500 | 1582 | 5646 | 11 | 0.4 | 16 | 82 | 362.0 |
| 242452 | 和田地区 | 2016-05-12 | 500 | 1528 | 3638 | 16 | 1.3 | 9 | 76 | 363.0 |
使用 query 方法(字符串表达式)
| cityname | time_point | aqi | pm25 | pm10 | so2 | co | no2 | o3 | rank | |
|---|---|---|---|---|---|---|---|---|---|---|
| 480272 | 南京 | 2013-12-04 | 386 | 336 | 455 | 51 | 2.5 | 130 | 43 | 109.0 |
| 480273 | 南京 | 2013-12-05 | 328 | 278 | 386 | 52 | 2.3 | 110 | 59 | 99.0 |
| 480274 | 南京 | 2013-12-06 | 319 | 269 | 389 | 61 | 2.2 | 92 | 36 | 99.0 |
| 480275 | 南京 | 2013-12-07 | 366 | 316 | 429 | 44 | 2.9 | 95 | 44 | 96.0 |
| 480293 | 南京 | 2013-12-25 | 307 | 257 | 383 | 138 | 2.7 | 136 | 22 | 82.0 |
| 480379 | 南京 | 2014-01-18 | 347 | 297 | 391 | 71 | 2.1 | 79 | 56 | 178.0 |
| 480380 | 南京 | 2014-01-19 | 327 | 277 | 371 | 67 | 2.0 | 88 | 80 | 173.0 |
使用正则表达式筛选字符串
| cityname | time_point | aqi | pm25 | pm10 | so2 | co | no2 | o3 | rank | |
|---|---|---|---|---|---|---|---|---|---|---|
| 327991 | 苏州 | 2013-12-05 | 305 | 255 | 288 | 40 | 2.3 | 126 | 52 | 94.0 |
| 327992 | 苏州 | 2013-12-06 | 412 | 368 | 373 | 40 | 2.9 | 105 | 12 | 109.0 |
| 328012 | 苏州 | 2013-12-26 | 312 | 262 | 315 | 66 | 2.4 | 105 | 19 | 111.0 |
| 480272 | 南京 | 2013-12-04 | 386 | 336 | 455 | 51 | 2.5 | 130 | 43 | 109.0 |
| 480273 | 南京 | 2013-12-05 | 328 | 278 | 386 | 52 | 2.3 | 110 | 59 | 99.0 |
| 480274 | 南京 | 2013-12-06 | 319 | 269 | 389 | 61 | 2.2 | 92 | 36 | 99.0 |
| 480275 | 南京 | 2013-12-07 | 366 | 316 | 429 | 44 | 2.9 | 95 | 44 | 96.0 |
| 480293 | 南京 | 2013-12-25 | 307 | 257 | 383 | 138 | 2.7 | 136 | 22 | 82.0 |
| 480379 | 南京 | 2014-01-18 | 347 | 297 | 391 | 71 | 2.1 | 79 | 56 | 178.0 |
| 480380 | 南京 | 2014-01-19 | 327 | 277 | 371 | 67 | 2.0 | 88 | 80 | 173.0 |
| 487925 | 南京 | 2017-12-31 | 304 | 0 | 0 | 17 | 2.3 | 89 | 50 | 328.0 |
筛选缺失值
删除重复行
删除完全重复的行
基于某些列删除重复行
| cityname | time_point | aqi | pm25 | pm10 | so2 | co | no2 | o3 | rank | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 长沙 | 2014-01-01 | 195 | 146 | 173 | 72 | 2.3 | 107 | 47 | 169.0 |
| 30 | 巴中 | 2018-12-01 | 39 | 27 | 37 | 4 | 1.0 | 24 | 11 | 27.0 |
| 56 | 宝鸡 | 2018-11-01 | 79 | 49 | 107 | 9 | 0.7 | 57 | 83 | 249.0 |
| 86 | 赤峰 | 2013-12-31 | 102 | 12 | 153 | 73 | 0.5 | 18 | 27 | 56.0 |
| 87 | 潮州 | 2018-10-01 | 103 | 34 | 58 | 9 | 0.9 | 13 | 163 | 163.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 514892 | 齐齐哈尔 | 2013-12-31 | 138 | 106 | 138 | 48 | 1.1 | 35 | 17 | 121.0 |
| 515241 | 绍兴 | 2013-12-02 | 137 | 105 | 162 | 70 | 1.9 | 91 | 34 | 46.0 |
| 515789 | 通化 | 2014-12-31 | 18 | 13 | 18 | 14 | 0.3 | 22 | 36 | 1.0 |
| 516366 | 四平 | 2014-12-31 | 56 | 31 | 63 | 56 | 1.0 | 17 | 39 | 68.0 |
| 516367 | 南平 | 2014-12-31 | 63 | 45 | 65 | 30 | 1.3 | 10 | 64 | 101.0 |
325 rows × 10 columns
聚合查询
分组操作将数据按照某个或某些列的值进行分组,然后对每个组进行聚合计算。
分组
分组通常是按照某一个或某几个列的值进行的,这些列的值需要可重复,才有分组的意义。这些列在统计学中被称为“层”或“因素”,变量类型通常是表示类别或序数的变量。
[('七台河',
cityname time_point aqi pm25 pm10 so2 co no2 o3 rank
257229 七台河 2017-10-01 75 22 98 10 0.5 13 98 44.0
257230 七台河 2017-10-02 39 14 36 11 0.3 20 56 38.0
257231 七台河 2017-10-03 46 16 46 12 0.4 24 51 89.0
257232 七台河 2017-10-04 51 20 56 13 0.4 26 68 218.0
257233 七台河 2017-10-05 60 24 71 14 0.5 32 88 254.0
... ... ... ... ... ... ... ... ... .. ...
533149 七台河 2017-09-27 48 13 46 10 0.3 18 67 79.0
533150 七台河 2017-09-28 44 14 51 10 0.3 18 64 89.0
533151 七台河 2017-09-29 50 14 48 11 0.3 18 59 19.0
533152 七台河 2017-09-30 59 18 69 12 0.4 22 57 122.0
534022 七台河 2018-12-27 60 21 69 7 0.5 24 54 105.0
[1457 rows x 10 columns]),
('三亚',
cityname time_point aqi pm25 pm10 so2 co no2 o3 rank
250773 三亚 2013-12-31 103 77 109 12 1.0 31 158 58.0
250987 三亚 2014-01-01 108 81 110 8 0.9 29 148 64.0
250988 三亚 2014-01-02 97 69 98 5 0.9 35 156 40.0
250989 三亚 2014-01-03 72 52 82 4 0.8 26 109 24.0
250990 三亚 2014-01-04 82 61 91 5 0.9 25 138 38.0
... ... ... ... ... ... ... ... ... ... ...
269246 三亚 2018-12-23 40 22 30 4 0.5 11 79 63.0
269247 三亚 2018-12-24 35 14 26 4 0.7 16 70 147.0
269248 三亚 2018-12-25 37 6 18 4 0.6 9 74 7.0
269249 三亚 2018-12-26 34 10 18 4 0.6 9 68 34.0
534054 三亚 2018-12-27 44 10 26 4 0.6 6 88 32.0
[1822 rows x 10 columns])]聚合后,每个元素是一个元组,第一个值代表组,第二个值是该组的数据。
cityname time_point aqi pm25 pm10 so2 co no2 o3 rank
257229 七台河 2017-10-01 75 22 98 10 0.5 13 98 44.0
257230 七台河 2017-10-02 39 14 36 11 0.3 20 56 38.0
257231 七台河 2017-10-03 46 16 46 12 0.4 24 51 89.0
257232 七台河 2017-10-04 51 20 56 13 0.4 26 68 218.0
257233 七台河 2017-10-05 60 24 71 14 0.5 32 88 254.0也可以按多列进行分组。
为了演示,这里生成一个年份的变量。
聚合
分组的目的是为了聚合查询,即对某个组的整体情况进行查询。
对分组进行聚合计算
常用的聚合函数:sum, mean, median, min, max, count, std, var, etc.
对多列进行聚合
同时使用多个聚合函数
| mean | std | max | min | |
|---|---|---|---|---|
| cityname | ||||
| 七台河 | 74.533288 | 42.843671 | 437 | 0 |
| 三亚 | 38.243139 | 17.971288 | 139 | 15 |
| 三明 | 50.266987 | 17.828725 | 183 | 16 |
| 三门峡 | 105.606814 | 59.676705 | 500 | 0 |
| 上海 | 82.859535 | 39.999361 | 468 | 0 |
| ... | ... | ... | ... | ... |
| 黔东南州 | 50.422787 | 22.305687 | 252 | 13 |
| 黔南州 | 49.899793 | 19.374351 | 122 | 0 |
| 黔西南州 | 43.258065 | 15.911391 | 128 | 17 |
| 齐齐哈尔 | 62.807355 | 38.702624 | 459 | 0 |
| 龙岩 | 49.660261 | 19.457527 | 256 | 13 |
325 rows × 4 columns
分组后筛选
| cityname | time_point | aqi | pm25 | pm10 | so2 | co | no2 | o3 | rank | year | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 109491 | 阿勒泰地区 | 2014-12-31 | 42 | 15 | 30 | 30 | 2.0 | 28 | 83 | 23.0 | 2014 |
| 109703 | 阿勒泰地区 | 2015-01-01 | 40 | 16 | 20 | 34 | 2.1 | 22 | 79 | 25.0 | 2015 |
| 109704 | 阿勒泰地区 | 2015-01-02 | 41 | 13 | 22 | 35 | 2.0 | 19 | 82 | 18.0 | 2015 |
| 109705 | 阿勒泰地区 | 2015-01-03 | 44 | 14 | 27 | 43 | 1.9 | 17 | 87 | 8.0 | 2015 |
| 109706 | 阿勒泰地区 | 2015-01-04 | 36 | 11 | 19 | 30 | 2.0 | 16 | 72 | 2.0 | 2015 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 196801 | 丽江 | 2018-12-24 | 32 | 14 | 28 | 8 | 0.9 | 14 | 64 | 75.0 | 2018 |
| 196802 | 丽江 | 2018-12-25 | 34 | 10 | 22 | 6 | 0.7 | 10 | 68 | 20.0 | 2018 |
| 196803 | 丽江 | 2018-12-26 | 35 | 12 | 24 | 6 | 0.6 | 13 | 69 | 12.0 | 2018 |
| 533932 | 阿勒泰地区 | 2018-12-27 | 28 | 15 | 16 | 9 | 0.6 | 11 | 55 | 170.0 | 2018 |
| 533979 | 丽江 | 2018-12-27 | 34 | 12 | 28 | 8 | 0.6 | 12 | 67 | 74.0 | 2018 |
2914 rows × 11 columns
分组后转换(对每个组进行计算,返回与原始数据相同长度的结果)
分组后应用自定义函数
数据可视化
数据可视化帮助我们直观地理解数据的分布、关系和趋势。我们将使用 matplotlib 和 seaborn 库进行绘图。
matplotlib 提供了与 Matlab 类似的函数接口,既可以轻松绘制多种图表,也可以对细节进行精确控制。
seaborn 在 matplotlib 的基础上进行了更高级的封装。
在开始绘图之前,我们可以设置全局的绘图样式,使图表更加美观。
将数据中的 time_point 转换从字符串转换为日期,并提取出南京的数据。
| cityname | time_point | aqi | pm25 | pm10 | so2 | co | no2 | o3 | rank | year | group_mean | date | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 480270 | 南京 | 2013-12-02 | 180 | 136 | 253 | 87 | 2.0 | 120 | 25 | 65.0 | 2013 | 93.793625 | 2013-12-02 |
| 480271 | 南京 | 2013-12-03 | 234 | 184 | 297 | 108 | 2.5 | 133 | 17 | 76.0 | 2013 | 93.793625 | 2013-12-03 |
| 480272 | 南京 | 2013-12-04 | 386 | 336 | 455 | 51 | 2.5 | 130 | 43 | 109.0 | 2013 | 93.793625 | 2013-12-04 |
| 480273 | 南京 | 2013-12-05 | 328 | 278 | 386 | 52 | 2.3 | 110 | 59 | 99.0 | 2013 | 93.793625 | 2013-12-05 |
| 480274 | 南京 | 2013-12-06 | 319 | 269 | 389 | 61 | 2.2 | 92 | 36 | 99.0 | 2013 | 93.793625 | 2013-12-06 |
基础统计图表
基础的统计图表通常是以下几种:
- 折线图:显示数据变化趋势
- 散点图:显示两个变量之间的关系
- 柱状图:比较数值大小
- 箱线图:展示数据的分布情况
- 直方图:展示数据的分布情况
- 热力图:展示矩阵数据
折线图(Line Plot)
折线图常用于显示数据随时间的变化趋势。
折线图(Line Plot)
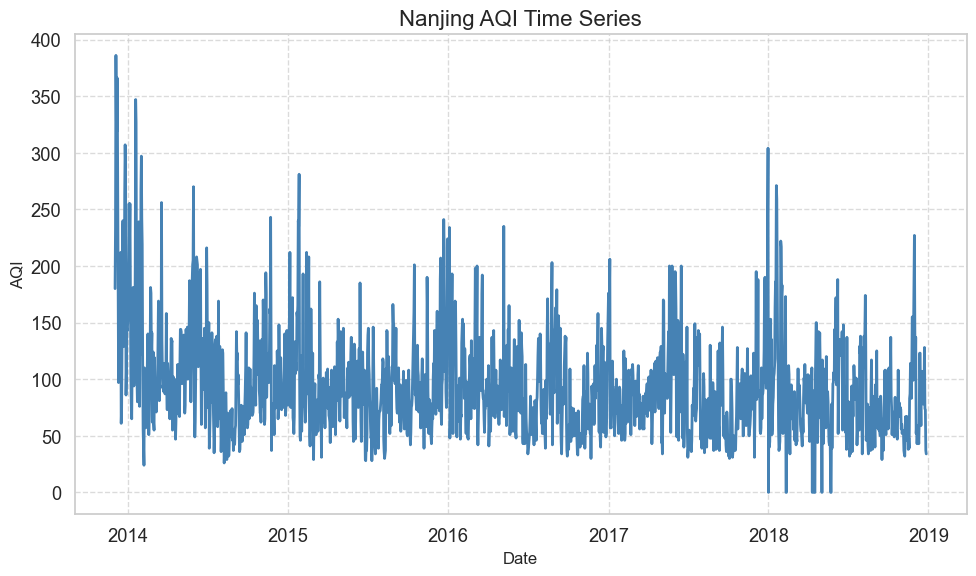
matplotlib 绘制折线图时,常用参数包括:
x:横坐标数据y:纵坐标数据color:线条颜色linestyle或ls:线型,如'-'、'--'、'-.'、':'linewidth或lw:线宽marker:数据点样式,如'o'、's'、'^'markersize或ms:数据点大小markerfacecolor:数据点填充颜色markeredgecolor:数据点边框颜色markeredgewidth:数据点边框宽度label:图例名称alpha:透明度zorder:图层顺序
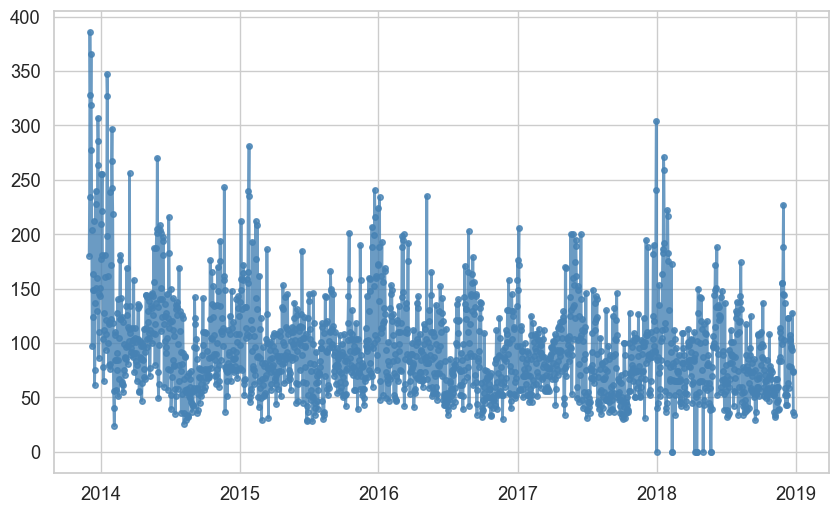
常配合使用的还有:
plt.title():标题plt.xlabel():横轴标签plt.ylabel():纵轴标签plt.legend():显示图例plt.grid():显示网格plt.tight_layout():自动调整布局
散点图(Scatter Plot)
散点图用于展示两个连续变量之间的关系。
散点图(Scatter Plot)
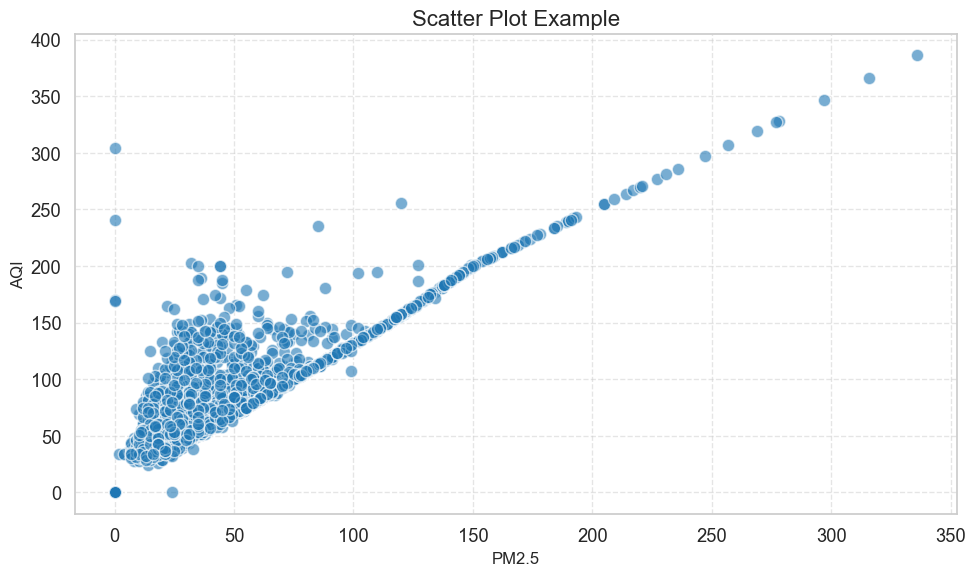
matplotlib 的 scatter() 常用可调整参数包括:
x,y:横纵坐标数据s:点的大小c:点的颜色marker:点的形状,如'o'、's'、'^'alpha:透明度edgecolors:点边框颜色linewidths:边框宽度cmap:颜色映射,适用于数值型颜色数据label:图例名称zorder:图层顺序vmin,vmax:颜色范围下限和上限
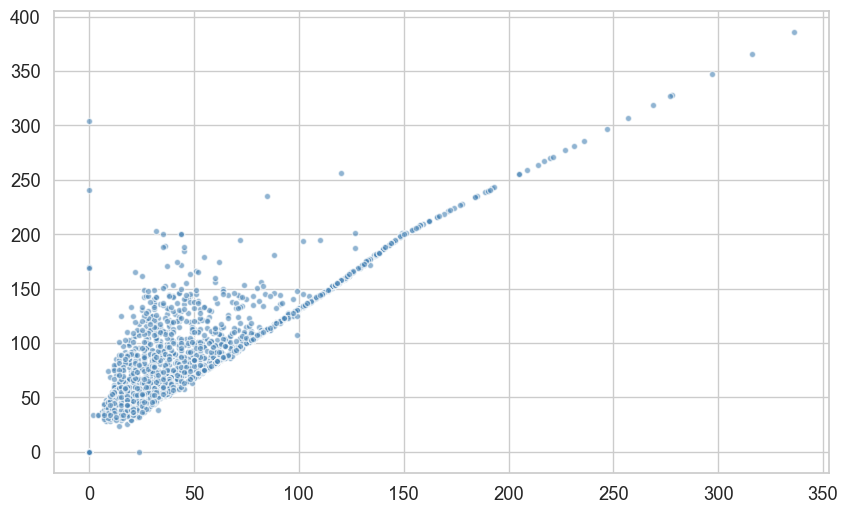
使用 seaborn 绘制带有回归线的散点图
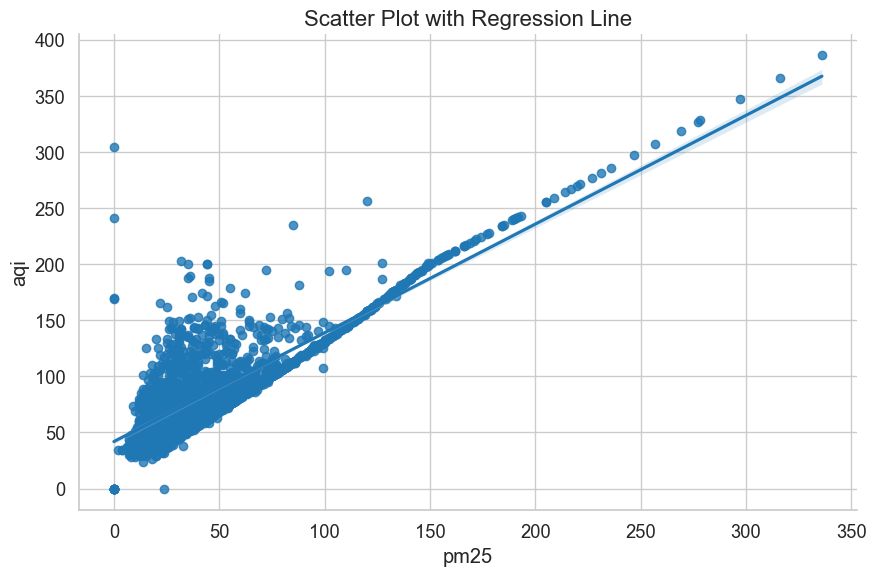
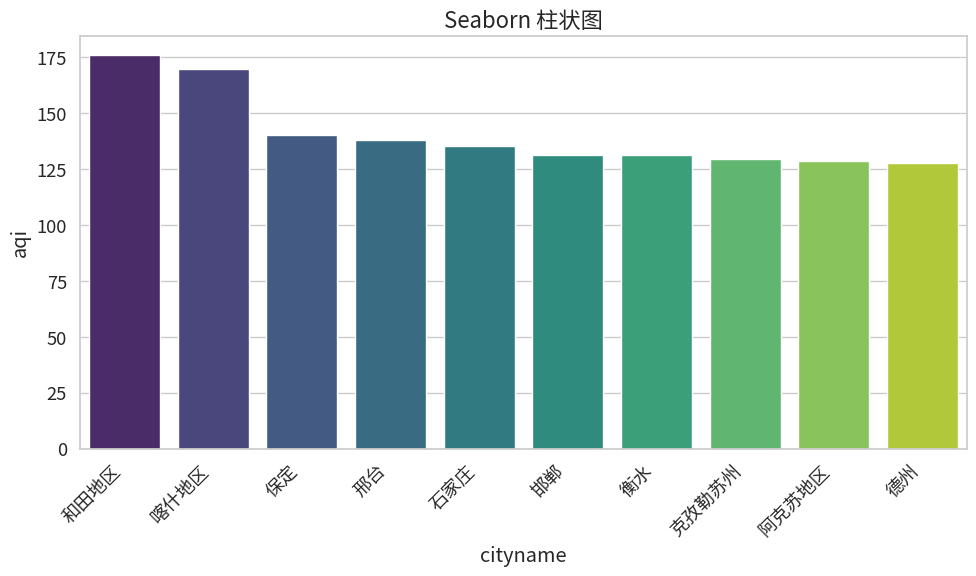
柱状图(Bar Plot)
柱状图用于比较不同类别的数值。
| aqi | |
|---|---|
| cityname | |
| 和田地区 | 176.027140 |
| 喀什地区 | 169.638947 |
| 保定 | 140.108093 |
| 邢台 | 138.219446 |
| 石家庄 | 135.435256 |
| 邯郸 | 131.587981 |
| 衡水 | 131.386031 |
| 克孜勒苏州 | 129.785813 |
| 阿克苏地区 | 128.740169 |
| 德州 | 127.958830 |
# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['Source Han Sans SC', 'Microsoft YaHei', 'Pingfang SC']
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 绘制柱状图
plt.bar(
aqi_city_mean_top10.index,
aqi_city_mean_top10['aqi'],
color='skyblue',
edgecolor='black'
)
plt.xticks(rotation=45, ha='right')
plt.title('City AQI Means', fontsize=16)
plt.xlabel('City', fontsize=12)
plt.ylabel('Mean AQI', fontsize=12)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()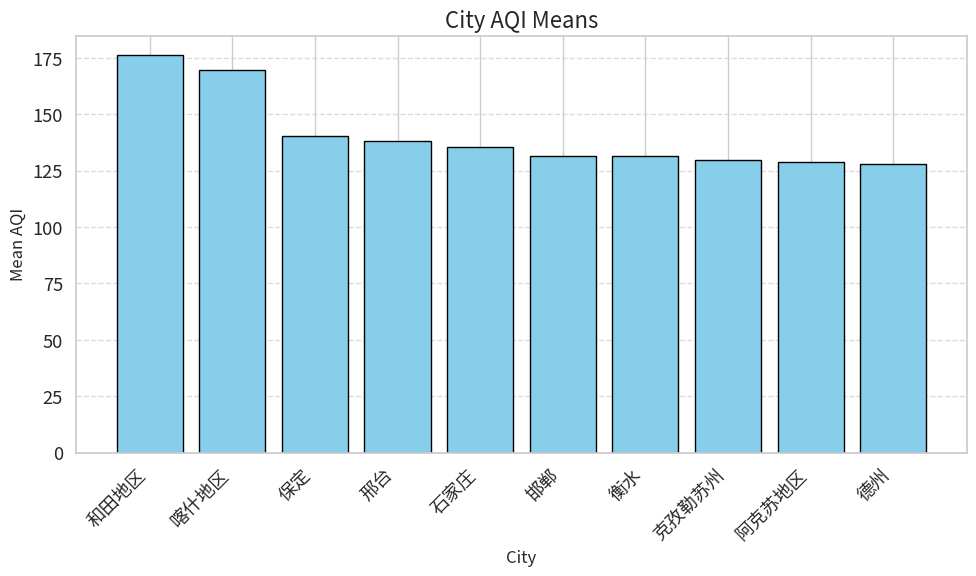
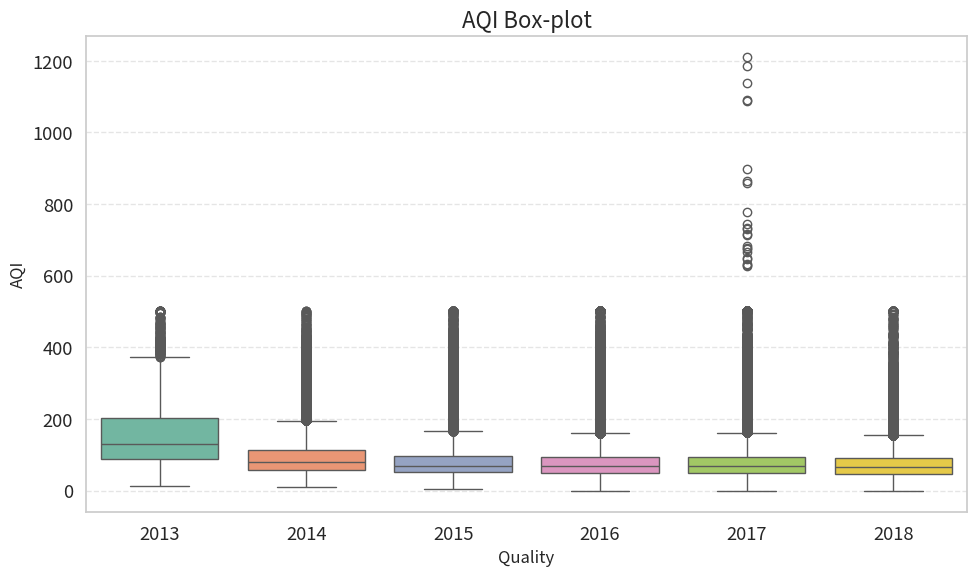
箱线图(Box Plot)
箱线图用于展示数据的分布情况,包括中位数、四分位数和异常值。
箱线图(Box Plot)
直方图(Histogram)
直方图用于展示单个连续变量的分布。
直方图(Histogram)
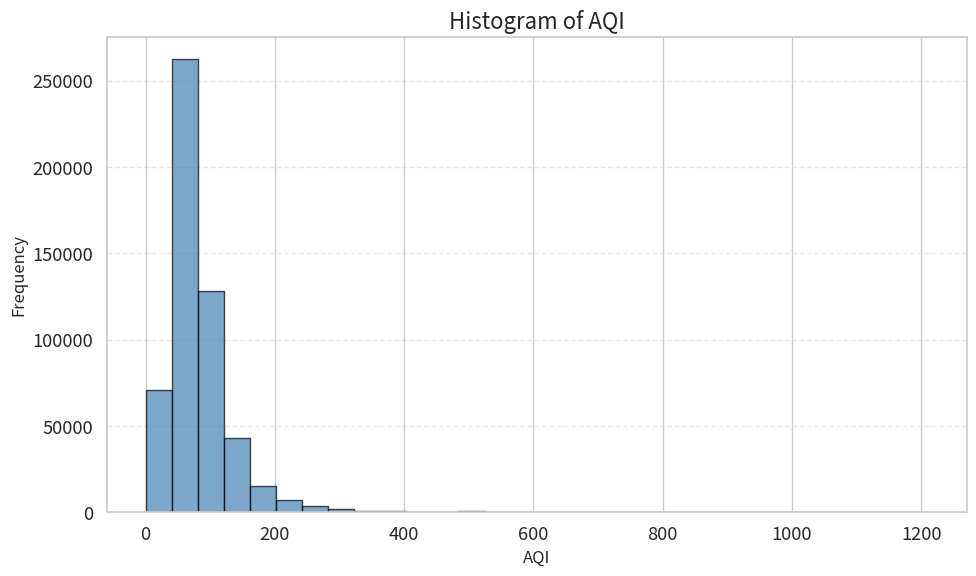
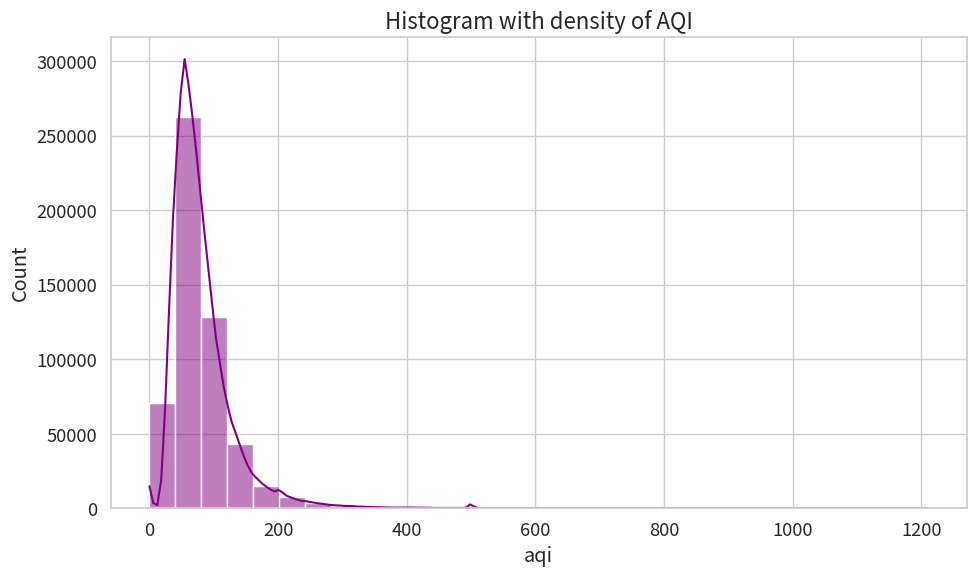
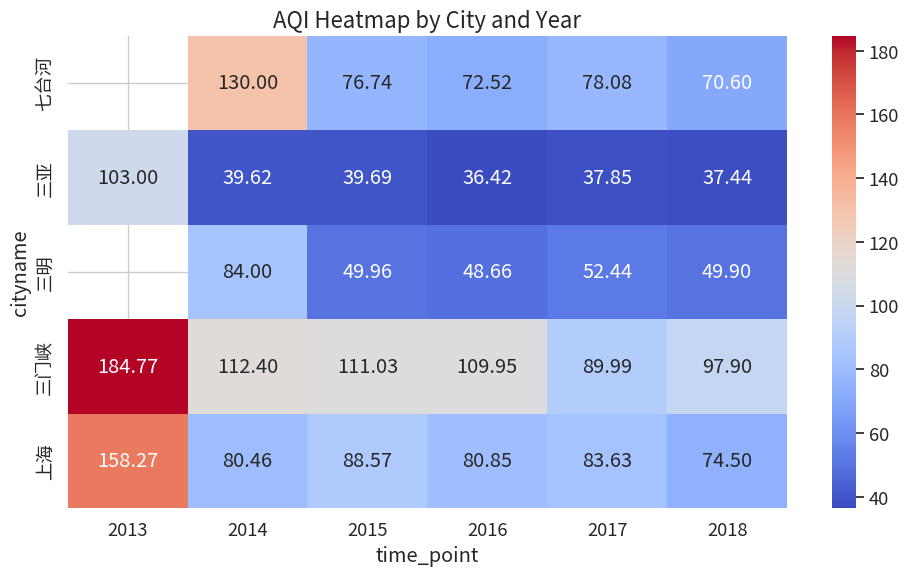
热力图(Heatmap)
热力图常用于展示矩阵数据。
将数据进行变换,展示5个城市6年AQI的变化情况。
| time_point | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 |
|---|---|---|---|---|---|---|
| cityname | ||||||
| 七台河 | NaN | 130.000000 | 76.736986 | 72.520548 | 78.082192 | 70.598338 |
| 三亚 | 103.000000 | 39.619178 | 39.687671 | 36.424658 | 37.854795 | 37.443213 |
| 三明 | NaN | 84.000000 | 49.961644 | 48.663014 | 52.443836 | 49.903047 |
| 三门峡 | 184.774194 | 112.397260 | 111.027624 | 109.953425 | 89.991781 | 97.900277 |
| 上海 | 158.266667 | 80.457534 | 88.572603 | 80.849315 | 83.630137 | 74.498615 |
多子图
有时我们需要在一个画布上绘制多个子图,以便比较不同视图。
# 创建2x2的子图布局
fig, axes = plt.subplots(2, 2, figsize=(8, 8))
# 第一个子图:折线图
axes[0, 0].plot(aqi['date'], aqi['aqi'], color='red')
axes[0, 0].set_title('AQI Time Series')
axes[0, 0].set_xlabel('Date')
axes[0, 0].set_ylabel('AQI')
axes[0, 0].grid(True, linestyle='--', alpha=0.5)
# 第二个子图:折线图
axes[0, 1].hist(aqi['aqi'], bins=30, color='blue')
axes[0, 1].set_title('AQI Distribution')
axes[0, 1].set_xlabel('AQI')
axes[0, 1].set_ylabel('Frequency')
axes[0, 1].grid(True, linestyle='--', alpha=0.5)
# 第三个子图:折线图
axes[1, 0].scatter(aqi['pm25'], aqi['aqi'], color='green')
axes[1, 0].set_title('AQI vs PM2.5')
axes[1, 0].set_xlabel('PM2.5')
axes[1, 0].set_ylabel('AQI')
axes[1, 0].grid(True, linestyle='--', alpha=0.5)
# 第四个子图:折线图(随机游走)
axes[1, 1].scatter(aqi['pm10'], aqi['aqi'], color='green')
axes[1, 1].set_title('AQI vs PM10')
axes[1, 1].set_xlabel('PM10')
axes[1, 1].set_ylabel('AQI')
axes[1, 1].grid(True, linestyle='--', alpha=0.5)
plt.suptitle('AQI Analysis', fontsize=18)
plt.tight_layout()
plt.show()多子图
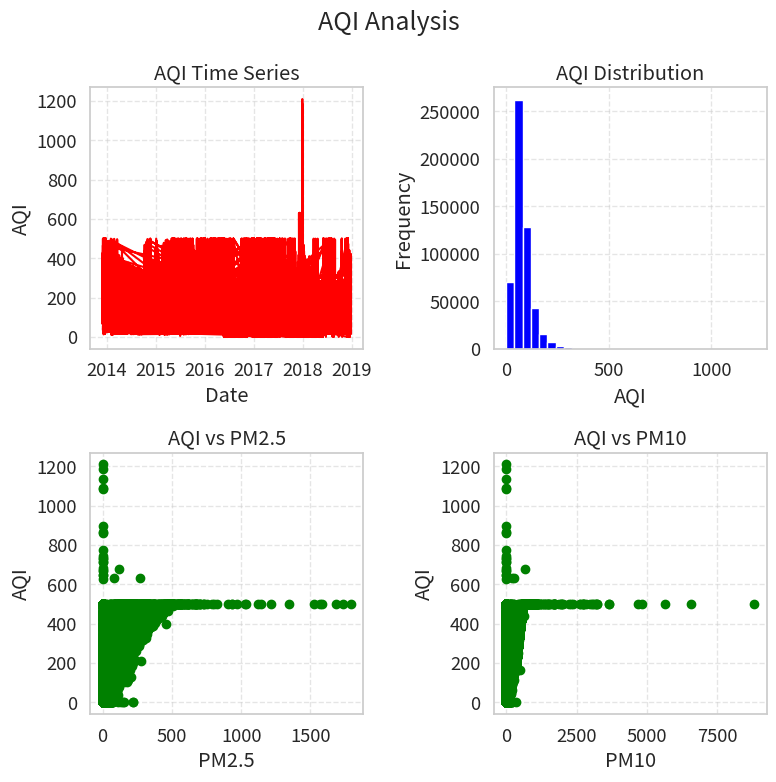
保存图表
绘制完图表后,我们可以将其保存为图片文件。
小结
本章介绍了 Python 数据分析的基础操作,包括数据文件的读写、数据查询和数据可视化。通过 pandas 库,我们可以轻松地读取和写入多种格式的数据文件,进行数据筛选和分组聚合。通过 matplotlib 和 seaborn 库,我们可以创建各种类型的图表,直观地展示数据特征。
在下一章中,我们将深入探讨基础数据处理,包括数据转换、缺失值处理、数据连接和基础统计分析。